Evaluating the Python TPCC MongoDB Benchmark

 I was looking for a tool that could evaluate MongoDB performance under a complex workload, besides simple key-value operations that benchmarks like YCSB provides.
I was looking for a tool that could evaluate MongoDB performance under a complex workload, besides simple key-value operations that benchmarks like YCSB provides.
That’s why the paper “Adapting TPC-C Benchmark to Measure Performance of Multi-Document Transactions in MongoDB” got my attention and I decided to try the tool https://github.com/mongodb-labs/py-tpcc mentioned in the paper.
Py-tpcc, as the name implies, tries to emulate queries and schema as specified in TPC-C specification, with the adaption of both schema and queries to MongoDB transactional dialect.
The concern I have about a benchmark using python script is that Python is known for high CPU consumption, and I want to evaluate if py-tpcc can provide the workload to fully utilize server capacity and if the bottleneck won’t be on the client-side itself, rather than on the server-side.
So let’s take a look at py-tpcc.
Hardware Specs
For the client and server, I will use identical bare metal servers, connected via 10Gb network.
The node specification:
# Percona Toolkit System Summary Report ######################
Hostname | beast-node4-ubuntu
System | Supermicro; SYS-F619P2-RTN; v0123456789 (Other)
Platform | Linux
Release | Ubuntu 18.04.4 LTS (bionic)
Kernel | 5.3.0-42-generic
Architecture | CPU = 64-bit, OS = 64-bit
# Processor ##################################################
Processors | physical = 2, cores = 40, virtual = 80, hyperthreading = yes
Models | 80xIntel(R) Xeon(R) Gold 6230 CPU @ 2.10GHz
Caches | 80x28160 KB
# Memory #####################################################
Total | 187.6G
Swappiness | 0
MongoDB Topology
For MongoDB I used a single node instance, configured as a non-sharded Replica Set with 1 node.
But First, An Aside – Using PyPy Makes Some Parts Much Better
The first step is to load data into the database, and actually I also wanted to compare different MongoDB versions, so these are the versions I tried:
- Percona Server for MongoDB 4.0.18-11
- Percona Server for MongoDB 4.2.7-7
- MongoDB Community 4.4-rc8 (the latest 4.4 version available as for the time of testing)
To load data with py-tpcc, we execute:
tpcc.py --config mconfig --warehouses 100 --no-execute mongodb
This will load the data for 100 warehouses (it should be about 10Gb of raw data). The first surprise comes from the execution time of this command.
For Percona Server for MongoDB 4.0.18-11 it was:
time ./tpcc.py --config mconfig --warehouses 100 --no-execute mongodb 2020-06-10 08:55:37,273 [<module>:245] INFO : Initializing TPC-C benchmark using MongodbDriver 2020-06-10 08:55:37,274 [<module>:255] INFO : Loading TPC-C benchmark data using MongodbDriver an real 87m45.815s user 83m3.677s sys 4m12.884s
That is 87min 45sec, which is too long.
When we try to profile it, we can see that the server-side is practically idle, and the client-side has 1 CPU core 100% busy, which indicates that the bottleneck is on the client data generation side.
How can we improve Python?
I personally followed project PyPy for quite a long time, so now it is a good time to see if using py-tpcc under PyPy will improve things:
time /mnt/data/vadim/bench/pypy2.7-v7.3.1-linux64/bin/pypy tpcc.py --config mconfig --warehouses 100 --no-execute mongodb 2020-06-10 12:00:16,647 [<module>:245] INFO : Initializing TPC-C benchmark using MongodbDriver 2020-06-10 12:00:16,647 [<module>:255] INFO : Loading TPC-C benchmark data using MongodbDriver real 9m34.223s user 5m29.182s sys 0m36.051s
Well, that’s quite an improvement. Now the execution time is 9m 34sec, instead of 87min 45 sec. 9 times faster! The resulting database size is 15GB.
Let’s compare load time for all MongoDB versions under PyPy:

It seems in 4.2 the load time increased, but then was improved in 4.4 version. Now that we have loaded the data, we can run the benchmark itself, as well.
I will run the benchmark for 900 sec, and the tool will report the amount of NEW_ORDER transactions executed during this time. I will also vary the number of concurrent clients from 10 to 250.
First, let’s see if using PyPy will improve the results.
I ran the benchmark against Percona Server for MongoDB 4.0.18-11. The results are in NEWORDER transactions per Minute.

TPM (Transactions per minute) with PyPy vs. normal Python (CPython)

PyPy improves the results, but in this case, not by 9x times like with load data. We also can compare CPU usage on the MongoDB server-side with running py-tpcc under PyPy and without PyPy:

Using the client with PyPy improves the server CPU utilization, with user+system CPU being over 80% for a high number of clients.
Py-tpcc Benchmark Results
So, I will continue to run py-tpcc under PyPy to compare different MongoDB versions
Result: NEWORDER transactions per Minute, TPM (more is better):
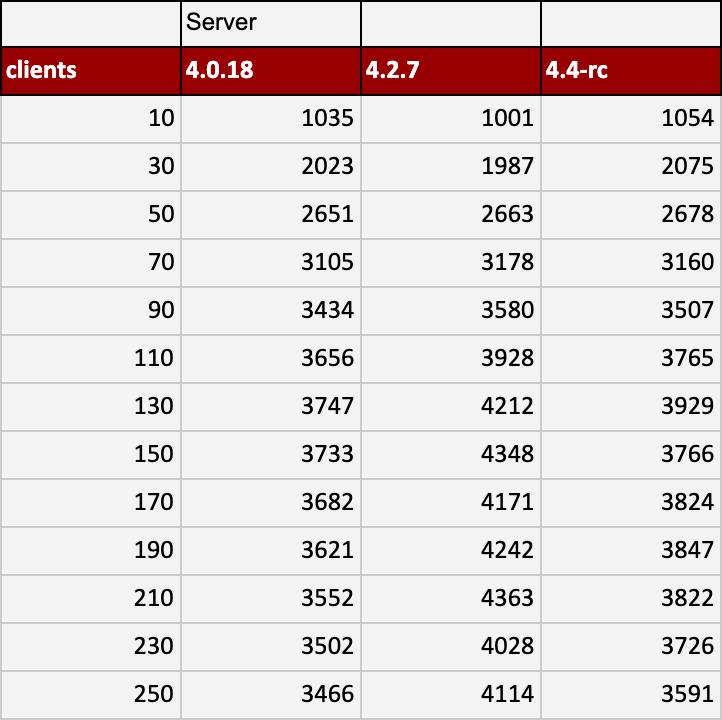

Some interesting observations:
- 4.2.7 performs worse on a small number of clients but scales better after 50 clients.
- For the reference, all servers were started as:
numactl --interleave=all ./mongod --dbpath=/data/mongo/ --bind_ip_all --replSet node2 --slowms=10000
Conclusions
I think the py-tpcc tool proposes an interesting workload for MongoDB evaluation, and I plan to use it in the future. It seems it is beneficial to use under the PyPy environment, especially to load data into the server.
Learn more about the history of Oracle, the growth of MongoDB, and what really qualifies software as open source. If you are a DBA, or an executive looking to adopt or renew with MongoDB, this is a must-read!
Download “Is MongoDB the New Oracle?”
by Vadim Tkachenko via Percona Database Performance Blog
Comments
Post a Comment